
Authors: Miguel Fernandes, Catarina Silva, Joel Arrais, Alberto Cardoso and Bernardete Ribeiro – University of Coimbra
Aircraft maintenance ensures that all the systems in the aircraft perform safely for the expected period of time. Maintenance checks have to be performed on each aircraft after reaching a certain number of flight hours. Another approach is preventive maintenance, namely Condition-Based Maintenance (CBM), where components historical data is used to create models that diagnose and predict future failures, then used to define maintenance plans.
The Advisory Council for Aeronautical Research in Europe (ACARE) predicts that, by 2050, all the new aircraft will be designed for CBM. The increasing capability of data analytics and the availability of sensor data allow for the creation of CBM methods that monitor the aircraft health, preventing redundant checks, leading to more efficient maintenance and cost reductions.
To create an CBM model huge amounts of data have to be gathered, which can be challenging in some cases due to data privacy and data ownership issues. At the University of Coimbra, we explore strategies to train and share CBM models without the need to share the data.
Streamlined CBM Pipeline
A CBM pipeline shows the steps that are necessary to take in order to have a condition prediction model.
The first step in this pipeline is to gather data that will be used to fit the model. Then data can be pre-processed to define the features that yield the most relevant information. The models we consider here are neural networks, a popular method in machine learning with the capability of capturing nonlinear relationships mapping inputs to outputs and resilient to noise. Afterwards, the model is trained using different techniques. Finally, this model will be able to evaluate the system’s condition.
As mentioned above, these methods need considerable amount of data. This is hardly achievable due to data sharing problems.
The Challenges of Data Sharing
Usually, data sharing is a cumbersome task and there are several obstacles associated with the sharing of data. Airlines have concerns on exposing themselves to liability and relinquish valuable confidential information. There are recurrent problems, such as, who owns the data, what are the rights involving the data, how data will be made available, and who will pay (Pool & Rusch, 2016).
These issues make it difficult for researchers that tackle the problem of CBM. In the following, we propose an approach to generate condition prediction models without the need to transfer private data.
Training Predictive Models Whilst Preserving Private Data
The idea is straightforward: we need to train condition predictive models without transferring private data. So, what can we do? We use a Decentralized Learning technology, more specifically Federated Learning (McMahan, Daniel, & Blaise, 2016). This method was proposed by Google AI researchers in 2017.
Federated Learning allows neural networks to be trained without transferring private data. Therefore, we can create CBM models that mitigate the sharing restrictions associated with data transferring. In addition, all of the model’s training is done by the participants of the federation.
First off, a participant receives a shared global model from the server and improves it by training with data only accessible to it. Then, it sends the updated model back to the server. In the server, the uploaded models are aggregated in order to form a new model. The most common method to aggregate the updates is Federated Averaging, in which the new update is calculated by a weighted average of the local parameter updates, assigning higher weight to the ones that used more data points.
Using this methodology, a group can use Federated Learning where CBM models can be developed without the members of the federation needing to make their private data available. Therefore, the model generation would become more agile, yielding better results.
Two Steps Beyond Federated Averaging
Federated Learning is a hot topic right now and as such researchers have been working with the purpose of improving this technology. In this newsletter, we propose two methods that have shown promised results by improving the convergence speed of the Federated Learning models: Federated Congruent Directional and Federated Momentum.
In a first method, an algorithm entitled Federated Congruent Directional Learning (FedCong) was created to choose which updates are going to be used to generate the new model. By looking at the local models update gradient direction the algorithm was able to mitigate the impact of bad local updates in the federated model. Figure 1 is a diagram that represents the pipeline of FedCong where ?t represents the global model, ?t+1k represents the k client uploaded model, nk is the amount of data used to train ?t+1k, ?(0,1) is a control parameter and n is the sum of all the nk.
In a second method, entitled Federated Momentum (FedMom), we were inspired by the idea of Momentum. The momentum parameter, on top of Stochastic Gradient Descent (common neural network optimization technique), has proven to accelerate the network’s training using the gradient history to dampen oscillations and take more straightforward paths to the local minimum (Qian, 1999) (Yang, Lin, & Li, 2016). Basically, the idea is to use Momentum on top of Federated Averaging. Figure 2 is a diagram that represents the pipeline of FedMom, where ?t represents the global model, ?t+1k represents the k client uploaded model, nk is the amount of data used to train ?t+1k, ?(0,1) is the momentum term and n is the sum of all the nk.
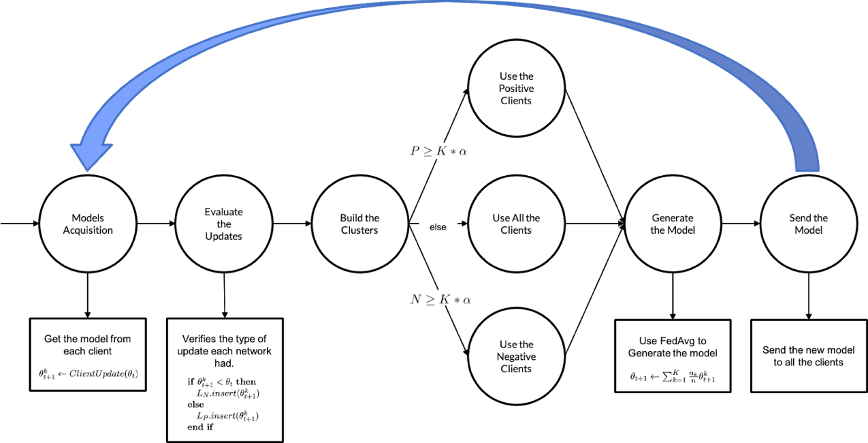
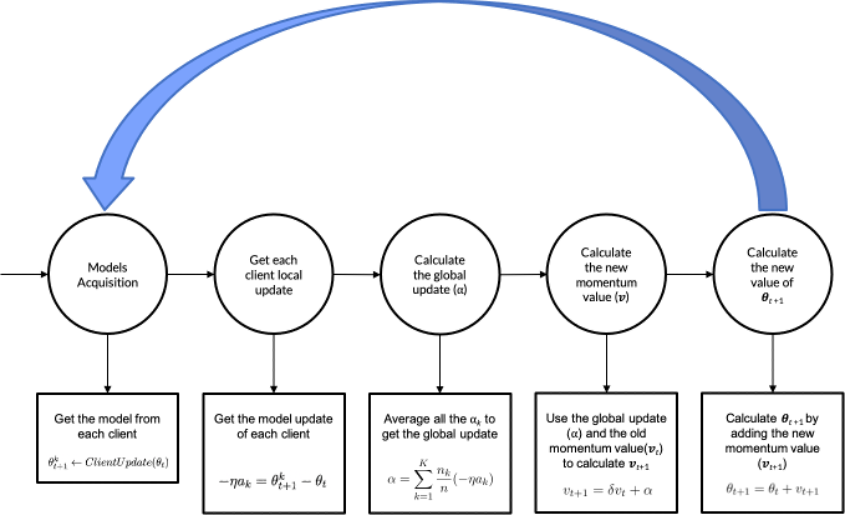
2. Federated Momentum (FedMom) Pipeline
The experimentation was done with a simple FeedForward Neural Network. The Network architecture is represented in Figure 3. Looking at the architecture, it can be observed that it has three hidden layers with 20, 30 and 20 neurons, respectively, with tanh activation functions. The output layer is a single neuron with a sigmoid activation function, which represents the predicted system’s Health (HI), 100% if totally healthy and 0% if failure. The local optimizer used predicted system’s Health (HI), 100% if totally healthy and 0% if failure. The local optimizer used was GD and the error function used was the Mean Square Error.
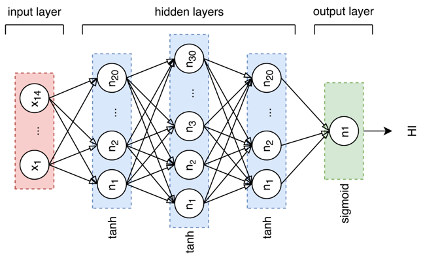
3. Representation of the network architecture where ni represents the i−th neuron. The function on the left side of each layer represents that layer’s activation function.
In Figure 4, the results of the proposed methods are presented where the Communication Round (Cr) is the instance when the federated model is generated. The experimentation was done using the Turbofan Dataset (Saxena & Goebel, 2008), commonly used in CBM. The step size η is similar between all the algorithms. The α and δ from FedCong and FedMom, respectively, were tuned in order to obtain the best performance.
By comparing these two methods with Federated Averaging, the results show an increase in the convergence speed, with the Momentum based method being the outstanding one, with an overall improvement of around 60%.
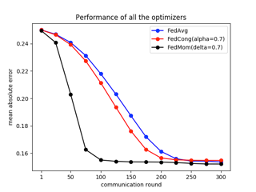
Although FedCong and FedMom showed an increase in the convergence speed of the models, some limitations should be considered. Firstly, in FedCong, it is of most importance to tune the control term, ?(0,1). If the value is low and the current aggregation round has a bad error representation, the global model error will fluctuate. As for FedMom, the momentum parameter ? has to be tuned in order for the model to converge. During a model’s update that has a poor representation of the global error, a large momentum term can cause the model to diverge even further and have constant fluctuations. In a number of cases a solution can be very difficult, if not impossible, to obtain.
Conclusion and Future Work
Federated Learning is a new technique that has the potential to solve the data sharing problem among companies and stakeholders while offering data-private model learning. In fact, the latter is deemed relevant by transferring model computation to the edge, only sending the updates to the server so we can keep data private. Both proposed algorithms increase the convergence speed of Federated Learning models, hence models can be generated faster by reducing the amount of data needed to be sent to the server. Future work will explore advanced federated settings for Condition Based Maintenance.
Bibliography
McMahan, H. B., D. R., & B. A. (2016). Communication-Efficient Learning of Deep Networks from Decentralized Data.
Huo, Z., Yang, Q., Gu, B., & Carin, L. (n.d.). Faster On-Device Training Using New Federated Momentum Algorithm.
Li, T., Sahu, A. K., Talwalkar, A., & Smith, V. (2020). Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Processing Magazine, 50–60.
Pool, R., & Rusch, E. (2016). Principles and Obstacles for Sharing Data from Environmental Health Research: Workshop Summary. National Academies Press.
Qian, N. (1999). On the momentum term in gradient descent learning algorithms. Neural Networks, 145 – 151.
Yang, T., Lin, Q., & Li, Z. (2016). Unified Convergence Analysis of Stochastic Momentum Methods for Convex and Non-convex Optimization.
Saxena, A., & Goebel, K. (2008). Turbofan Engine Degradation Simulation Data Set. Retrieved from https://ti.arc.nasa.gov/c/13/



